Content from (ProgWerk) Python Fundamentals
Last updated on 2024-03-10 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- What basic data types can I work with in Python?
- How can I create a new variable in Python?
- How do I use a function?
- Can I change the value associated with a variable after I create it?
Objectives
- Assign values to variables.
Programmier-Werkstatt 2024
Diese Website ist ein Fork von dem Python Kurs von Software Carpentry.
Wir haben ein paar Lektionen rund um Data Science rausgenommen und angepasst. Falls dich Data Science interessiert, ist das Original für dich möglicherweise besser geeignet als dieser Fork.
Variables
Any Python interpreter can be used as a calculator:
OUTPUT
23This is great but not very interesting. To do anything useful with
data, we need to assign its value to a variable. In Python, we
can assign a value to a variable, using the equals sign
=. For example, we can track the weight of a patient who
weighs 60 kilograms by assigning the value 60 to a variable
weight_kg:
From now on, whenever we use weight_kg, Python will
substitute the value we assigned to it. In layperson’s terms, a
variable is a name for a value.
In Python, variable names:
- can include letters, digits, and underscores
- cannot start with a digit
- are case sensitive.
This means that, for example:
-
weight0is a valid variable name, whereas0weightis not -
weightandWeightare different variables
Types of data
Python knows various types of data. Three common ones are:
- integer numbers
- floating point numbers, and
- strings.
In the example above, variable weight_kg has an integer
value of 60. If we want to more precisely track the weight
of our patient, we can use a floating point value by executing:
To create a string, we add single or double quotes around some text. To identify and track a patient throughout our study, we can assign each person a unique identifier by storing it in a string:
Using Variables in Python
Once we have data stored with variable names, we can make use of it in calculations. We may want to store our patient’s weight in pounds as well as kilograms:
We might decide to add a prefix to our patient identifier:
Built-in Python functions
To carry out common tasks with data and variables in Python, the
language provides us with several built-in functions. To display information to
the screen, we use the print function:
OUTPUT
132.66
inflam_001When we want to make use of a function, referred to as calling the
function, we follow its name by parentheses. The parentheses are
important: if you leave them off, the function doesn’t actually run!
Sometimes you will include values or variables inside the parentheses
for the function to use. In the case of print, we use the
parentheses to tell the function what value we want to display. We will
learn more about how functions work and how to create our own in later
episodes.
We can display multiple things at once using only one
print call:
OUTPUT
inflam_001 weight in kilograms: 60.3We can also call a function inside of another function call. For example,
Python has a built-in function called type that tells you a
value’s data type:
OUTPUT
<class 'float'>
<class 'str'>Moreover, we can do arithmetic with variables right inside the
print function:
OUTPUT
weight in pounds: 132.66The above command, however, did not change the value of
weight_kg:
OUTPUT
60.3To change the value of the weight_kg variable, we have
to assign weight_kg a new value using the
equals = sign:
OUTPUT
weight in kilograms is now: 65.0Variables as Sticky Notes
A variable in Python is analogous to a sticky note with a name written on it: assigning a value to a variable is like putting that sticky note on a particular value.

Using this analogy, we can investigate how assigning a value to one variable does not change values of other, seemingly related, variables. For example, let’s store the subject’s weight in pounds in its own variable:
PYTHON
# There are 2.2 pounds per kilogram
weight_lb = 2.2 * weight_kg
print('weight in kilograms:', weight_kg, 'and in pounds:', weight_lb)OUTPUT
weight in kilograms: 65.0 and in pounds: 143.0Everything in a line of code following the ‘#’ symbol is a comment that is ignored by Python. Comments allow programmers to leave explanatory notes for other programmers or their future selves.

Similar to above, the expression 2.2 * weight_kg is
evaluated to 143.0, and then this value is assigned to the
variable weight_lb (i.e. the sticky note
weight_lb is placed on 143.0). At this point,
each variable is “stuck” to completely distinct and unrelated
values.
Let’s now change weight_kg:
PYTHON
weight_kg = 100.0
print('weight in kilograms is now:', weight_kg, 'and weight in pounds is still:', weight_lb)OUTPUT
weight in kilograms is now: 100.0 and weight in pounds is still: 143.0
Since weight_lb doesn’t “remember” where its value comes
from, it is not updated when we change weight_kg.
OUTPUT
`mass` holds a value of 47.5, `age` does not exist
`mass` still holds a value of 47.5, `age` holds a value of 122
`mass` now has a value of 95.0, `age`'s value is still 122
`mass` still has a value of 95.0, `age` now holds 102OUTPUT
Hopper GraceKey Points
- Basic data types in Python include integers, strings, and floating-point numbers.
- Use
variable = valueto assign a value to a variable in order to record it in memory. - Variables are created on demand whenever a value is assigned to them.
- Use
print(something)to display the value ofsomething. - Use
# some kind of explanationto add comments to programs. - Built-in functions are always available to use.
Content from (ProgWerk) Storing Multiple Values in Lists
Last updated on 2024-03-10 | Edit this page
Estimated time: 45 minutes
Overview
Questions
- How can I store many values together?
Objectives
- Explain what a list is.
- Create and index lists of simple values.
- Change the values of individual elements
- Append values to an existing list
- Reorder and slice list elements
- Create and manipulate nested lists
In the previous episode, we analyzed a single file of clinical trial inflammation data. However, after finding some peculiar and potentially suspicious trends in the trial data we ask Dr. Maverick if they have performed any other clinical trials. Surprisingly, they say that they have and provide us with 11 more CSV files for a further 11 clinical trials they have undertaken since the initial trial.
Our goal now is to process all the inflammation data we have, which means that we still have eleven more files to go!
The natural first step is to collect the names of all the files that we have to process. In Python, a list is a way to store multiple values together. In this episode, we will learn how to store multiple values in a list as well as how to work with lists.
Python lists
Unlike NumPy arrays, lists are built into the language so we do not have to load a library to use them. We create a list by putting values inside square brackets and separating the values with commas:
OUTPUT
odds are: [1, 3, 5, 7]We can access elements of a list using indices – numbered positions of elements in the list. These positions are numbered starting at 0, so the first element has an index of 0.
PYTHON
print('first element:', odds[0])
print('last element:', odds[3])
print('"-1" element:', odds[-1])OUTPUT
first element: 1
last element: 7
"-1" element: 7Yes, we can use negative numbers as indices in Python. When we do so,
the index -1 gives us the last element in the list,
-2 the second to last, and so on. Because of this,
odds[3] and odds[-1] point to the same element
here.
There is one important difference between lists and strings: we can change the values in a list, but we cannot change individual characters in a string. For example:
PYTHON
names = ['Curie', 'Darwing', 'Turing'] # typo in Darwin's name
print('names is originally:', names)
names[1] = 'Darwin' # correct the name
print('final value of names:', names)OUTPUT
names is originally: ['Curie', 'Darwing', 'Turing']
final value of names: ['Curie', 'Darwin', 'Turing']works, but:
ERROR
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-220df48aeb2e> in <module>()
1 name = 'Darwin'
----> 2 name[0] = 'd'
TypeError: 'str' object does not support item assignmentdoes not.
Ch-Ch-Ch-Ch-Changes
Data which can be modified in place is called mutable, while data which cannot be modified is called immutable. Strings and numbers are immutable. This does not mean that variables with string or number values are constants, but when we want to change the value of a string or number variable, we can only replace the old value with a completely new value.
Lists and arrays, on the other hand, are mutable: we can modify them after they have been created. We can change individual elements, append new elements, or reorder the whole list. For some operations, like sorting, we can choose whether to use a function that modifies the data in-place or a function that returns a modified copy and leaves the original unchanged.
Be careful when modifying data in-place. If two variables refer to the same list, and you modify the list value, it will change for both variables!
PYTHON
mild_salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
hot_salsa = mild_salsa # <-- mild_salsa and hot_salsa point to the *same* list data in memory
hot_salsa[0] = 'hot peppers'
print('Ingredients in mild salsa:', mild_salsa)
print('Ingredients in hot salsa:', hot_salsa)OUTPUT
Ingredients in mild salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']
Ingredients in hot salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']If you want variables with mutable values to be independent, you must make a copy of the value when you assign it.
PYTHON
mild_salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
hot_salsa = list(mild_salsa) # <-- makes a *copy* of the list
hot_salsa[0] = 'hot peppers'
print('Ingredients in mild salsa:', mild_salsa)
print('Ingredients in hot salsa:', hot_salsa)OUTPUT
Ingredients in mild salsa: ['peppers', 'onions', 'cilantro', 'tomatoes']
Ingredients in hot salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']Because of pitfalls like this, code which modifies data in place can be more difficult to understand. However, it is often far more efficient to modify a large data structure in place than to create a modified copy for every small change. You should consider both of these aspects when writing your code.
Nested Lists
Since a list can contain any Python variables, it can even contain other lists.
For example, you could represent the products on the shelves of a
small grocery shop as a nested list called veg:

To store the contents of the shelf in a nested list, you write it this way:
PYTHON
veg = [['lettuce', 'lettuce', 'peppers', 'zucchini'],
['lettuce', 'lettuce', 'peppers', 'zucchini'],
['lettuce', 'cilantro', 'peppers', 'zucchini']]Here are some visual examples of how indexing a list of lists
veg works. First, you can reference each row on the shelf
as a separate list. For example, veg[2] represents the
bottom row, which is a list of the baskets in that row.
![veg is now shown as a list of three rows, with veg[0] representing the top row ofthree baskets, veg[1] representing the second row, and veg[2] representing the bottom row.](../fig/04_groceries_veg0.png)
Index operations using the image would work like this:
OUTPUT
['lettuce', 'cilantro', 'peppers', 'zucchini']OUTPUT
['lettuce', 'lettuce', 'peppers', 'zucchini']To reference a specific basket on a specific shelf, you use two
indexes. The first index represents the row (from top to bottom) and the
second index represents the specific basket (from left to right). ![veg is now shown as a two-dimensional grid, with each basket labeled according toits index in the nested list. The first index is the row number and the secondindex is the basket number, so veg[1][3] represents the basket on the far rightside of the second row (basket 4 on row 2): zucchini](../fig/04_groceries_veg00.png)
OUTPUT
'lettuce'OUTPUT
'peppers'There are many ways to change the contents of lists besides assigning new values to individual elements:
OUTPUT
odds after adding a value: [1, 3, 5, 7, 11]PYTHON
removed_element = odds.pop(0)
print('odds after removing the first element:', odds)
print('removed_element:', removed_element)OUTPUT
odds after removing the first element: [3, 5, 7, 11]
removed_element: 1OUTPUT
odds after reversing: [11, 7, 5, 3]While modifying in place, it is useful to remember that Python treats lists in a slightly counter-intuitive way.
As we saw earlier, when we modified the mild_salsa list
item in-place, if we make a list, (attempt to) copy it and then modify
this list, we can cause all sorts of trouble. This also applies to
modifying the list using the above functions:
PYTHON
odds = [3, 5, 7]
primes = odds
primes.append(2)
print('primes:', primes)
print('odds:', odds)OUTPUT
primes: [3, 5, 7, 2]
odds: [3, 5, 7, 2]This is because Python stores a list in memory, and then can use
multiple names to refer to the same list. If all we want to do is copy a
(simple) list, we can again use the list function, so we do
not modify a list we did not mean to:
PYTHON
odds = [3, 5, 7]
primes = list(odds)
primes.append(2)
print('primes:', primes)
print('odds:', odds)OUTPUT
primes: [3, 5, 7, 2]
odds: [3, 5, 7]Subsets of lists and strings can be accessed by specifying ranges of values in brackets, similar to how we accessed ranges of positions in a NumPy array. This is commonly referred to as “slicing” the list/string.
PYTHON
binomial_name = 'Drosophila melanogaster'
group = binomial_name[0:10]
print('group:', group)
species = binomial_name[11:23]
print('species:', species)
chromosomes = ['X', 'Y', '2', '3', '4']
autosomes = chromosomes[2:5]
print('autosomes:', autosomes)
last = chromosomes[-1]
print('last:', last)OUTPUT
group: Drosophila
species: melanogaster
autosomes: ['2', '3', '4']
last: 4Slicing From the End
Use slicing to access only the last four characters of a string or entries of a list.
PYTHON
string_for_slicing = 'Observation date: 02-Feb-2013'
list_for_slicing = [['fluorine', 'F'],
['chlorine', 'Cl'],
['bromine', 'Br'],
['iodine', 'I'],
['astatine', 'At']]OUTPUT
'2013'
[['chlorine', 'Cl'], ['bromine', 'Br'], ['iodine', 'I'], ['astatine', 'At']]Would your solution work regardless of whether you knew beforehand the length of the string or list (e.g. if you wanted to apply the solution to a set of lists of different lengths)? If not, try to change your approach to make it more robust.
Hint: Remember that indices can be negative as well as positive
Non-Continuous Slices
So far we’ve seen how to use slicing to take single blocks of successive entries from a sequence. But what if we want to take a subset of entries that aren’t next to each other in the sequence?
You can achieve this by providing a third argument to the range within the brackets, called the step size. The example below shows how you can take every third entry in a list:
PYTHON
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[0:12:3]
print('subset', subset)OUTPUT
subset [2, 7, 17, 29]Notice that the slice taken begins with the first entry in the range, followed by entries taken at equally-spaced intervals (the steps) thereafter. If you wanted to begin the subset with the third entry, you would need to specify that as the starting point of the sliced range:
PYTHON
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[2:12:3]
print('subset', subset)OUTPUT
subset [5, 13, 23, 37]Use the step size argument to create a new string that contains only every other character in the string “In an octopus’s garden in the shade”. Start with creating a variable to hold the string:
What slice of beatles will produce the following output
(i.e., the first character, third character, and every other character
through the end of the string)?
OUTPUT
I notpssgre ntesaeIf you want to take a slice from the beginning of a sequence, you can omit the first index in the range:
PYTHON
date = 'Monday 4 January 2016'
day = date[0:6]
print('Using 0 to begin range:', day)
day = date[:6]
print('Omitting beginning index:', day)OUTPUT
Using 0 to begin range: Monday
Omitting beginning index: MondayAnd similarly, you can omit the ending index in the range to take a slice to the very end of the sequence:
PYTHON
months = ['jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jul', 'aug', 'sep', 'oct', 'nov', 'dec']
sond = months[8:12]
print('With known last position:', sond)
sond = months[8:len(months)]
print('Using len() to get last entry:', sond)
sond = months[8:]
print('Omitting ending index:', sond)OUTPUT
With known last position: ['sep', 'oct', 'nov', 'dec']
Using len() to get last entry: ['sep', 'oct', 'nov', 'dec']
Omitting ending index: ['sep', 'oct', 'nov', 'dec']Overloading
+ usually means addition, but when used on strings or
lists, it means “concatenate”. Given that, what do you think the
multiplication operator * does on lists? In particular,
what will be the output of the following code?
[2, 4, 6, 8, 10, 2, 4, 6, 8, 10][4, 8, 12, 16, 20][[2, 4, 6, 8, 10], [2, 4, 6, 8, 10]][2, 4, 6, 8, 10, 4, 8, 12, 16, 20]
The technical term for this is operator overloading: a
single operator, like + or *, can do different
things depending on what it’s applied to.
Key Points
-
[value1, value2, value3, ...]creates a list. - Lists can contain any Python object, including lists (i.e., list of lists).
- Lists are indexed and sliced with square brackets (e.g.,
list[0]andlist[2:9]), in the same way as strings and arrays. - Lists are mutable (i.e., their values can be changed in place).
- Strings are immutable (i.e., the characters in them cannot be changed).
Content from (ProgWerk) Repeating Actions with Loops
Last updated on 2024-03-10 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How can I do the same operations on many different values?
Objectives
- Explain what a
forloop does. - Correctly write
forloops to repeat simple calculations. - Trace changes to a loop variable as the loop runs.
- Trace changes to other variables as they are updated by a
forloop.
In the episode about visualizing data, we wrote Python code that
plots values of interest from our first inflammation dataset
(inflammation-01.csv), which revealed some suspicious
features in it.
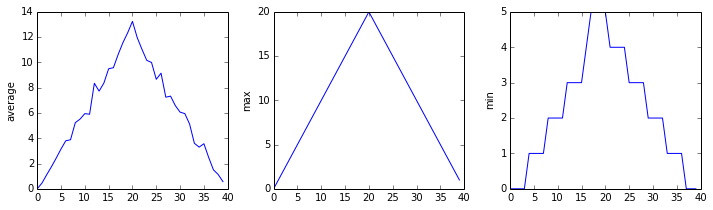
We have a dozen data sets right now and potentially more on the way if Dr. Maverick can keep up their surprisingly fast clinical trial rate. We want to create plots for all of our data sets with a single statement. To do that, we’ll have to teach the computer how to repeat things.
An example task that we might want to repeat is accessing numbers in a list, which we will do by printing each number on a line of its own.
In Python, a list is basically an ordered collection of elements, and
every element has a unique number associated with it — its index. This
means that we can access elements in a list using their indices. For
example, we can get the first number in the list odds, by
using odds[0]. One way to print each number is to use four
print statements:
OUTPUT
1
3
5
7This is a bad approach for three reasons:
Not scalable. Imagine you need to print a list that has hundreds of elements. It might be easier to type them in manually.
Difficult to maintain. If we want to decorate each printed element with an asterisk or any other character, we would have to change four lines of code. While this might not be a problem for small lists, it would definitely be a problem for longer ones.
Fragile. If we use it with a list that has more elements than what we initially envisioned, it will only display part of the list’s elements. A shorter list, on the other hand, will cause an error because it will be trying to display elements of the list that do not exist.
OUTPUT
1
3
5ERROR
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-3-7974b6cdaf14> in <module>()
3 print(odds[1])
4 print(odds[2])
----> 5 print(odds[3])
IndexError: list index out of rangeHere’s a better approach: a for loop
OUTPUT
1
3
5
7This is shorter — certainly shorter than something that prints every number in a hundred-number list — and more robust as well:
OUTPUT
1
3
5
7
9
11The improved version uses a for loop to repeat an operation — in this case, printing — once for each thing in a sequence. The general form of a loop is:
Using the odds example above, the loop might look like this:
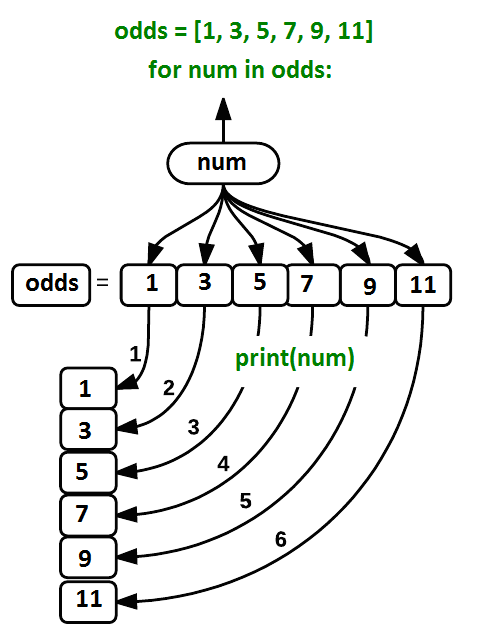
where each number (num) in the variable
odds is looped through and printed one number after
another. The other numbers in the diagram denote which loop cycle the
number was printed in (1 being the first loop cycle, and 6 being the
final loop cycle).
We can call the loop
variable anything we like, but there must be a colon at the end of
the line starting the loop, and we must indent anything we want to run
inside the loop. Unlike many other languages, there is no command to
signify the end of the loop body (e.g. end for); everything
indented after the for statement belongs to the loop.
What’s in a name?
In the example above, the loop variable was given the name
num as a mnemonic; it is short for ‘number’. We can choose
any name we want for variables. We might just as easily have chosen the
name banana for the loop variable, as long as we use the
same name when we invoke the variable inside the loop:
OUTPUT
1
3
5
7
9
11It is a good idea to choose variable names that are meaningful, otherwise it would be more difficult to understand what the loop is doing.
Here’s another loop that repeatedly updates a variable:
PYTHON
length = 0
names = ['Curie', 'Darwin', 'Turing']
for value in names:
length = length + 1
print('There are', length, 'names in the list.')OUTPUT
There are 3 names in the list.It’s worth tracing the execution of this little program step by step.
Since there are three names in names, the statement on line
4 will be executed three times. The first time around,
length is zero (the value assigned to it on line 1) and
value is Curie. The statement adds 1 to the
old value of length, producing 1, and updates
length to refer to that new value. The next time around,
value is Darwin and length is 1,
so length is updated to be 2. After one more update,
length is 3; since there is nothing left in
names for Python to process, the loop finishes and the
print function on line 5 tells us our final answer.
Note that a loop variable is a variable that is being used to record progress in a loop. It still exists after the loop is over, and we can re-use variables previously defined as loop variables as well:
PYTHON
name = 'Rosalind'
for name in ['Curie', 'Darwin', 'Turing']:
print(name)
print('after the loop, name is', name)OUTPUT
Curie
Darwin
Turing
after the loop, name is TuringNote also that finding the length of an object is such a common
operation that Python actually has a built-in function to do it called
len:
OUTPUT
4len is much faster than any function we could write
ourselves, and much easier to read than a two-line loop; it will also
give us the length of many other things that we haven’t met yet, so we
should always use it when we can.
From 1 to N
Python has a built-in function called range that
generates a sequence of numbers. range can accept 1, 2, or
3 parameters.
- If one parameter is given,
rangegenerates a sequence of that length, starting at zero and incrementing by 1. For example,range(3)produces the numbers0, 1, 2. - If two parameters are given,
rangestarts at the first and ends just before the second, incrementing by one. For example,range(2, 5)produces2, 3, 4. - If
rangeis given 3 parameters, it starts at the first one, ends just before the second one, and increments by the third one. For example,range(3, 10, 2)produces3, 5, 7, 9.
Using range, write a loop that prints the first 3
natural numbers:
The body of the loop is executed 6 times.
Computing the Value of a Polynomial
The built-in function enumerate takes a sequence (e.g. a
list) and generates a new sequence of the
same length. Each element of the new sequence is a pair composed of the
index (0, 1, 2,…) and the value from the original sequence:
The code above loops through a_list, assigning the index
to idx and the value to val.
Suppose you have encoded a polynomial as a list of coefficients in the following way: the first element is the constant term, the second element is the coefficient of the linear term, the third is the coefficient of the quadratic term, etc.
OUTPUT
97Write a loop using enumerate(coefs) which computes the
value y of any polynomial, given x and
coefs.
Content from (ProgWerk) Making Choices
Last updated on 2024-03-10 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How can my programs do different things based on data values?
Objectives
- Write conditional statements including
if,elif, andelsebranches. - Correctly evaluate expressions containing
andandor.
In our last lesson, we discovered something suspicious was going on in our inflammation data by drawing some plots. How can we use Python to automatically recognize the different features we saw, and take a different action for each? In this lesson, we’ll learn how to write code that runs only when certain conditions are true.
Conditionals
We can ask Python to take different actions, depending on a
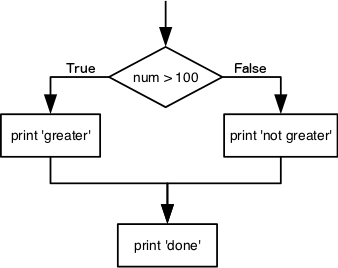
condition, with an if statement:
The following example will lead to a syntax error in the Python
prompt, as it seems to expect exactly one top-level statement per
invocation. Removing print('done') from the example will
fix the problem.
IPython executes the example from a single prompt without throwing an error.
OUTPUT
not greater
doneThe second line of this code uses the keyword if to tell
Python that we want to make a choice. If the test that follows the
if statement is true, the body of the if
(i.e., the set of lines indented underneath it) is executed, and
“greater” is printed. If the test is false, the body of the
else is executed instead, and “not greater” is printed.
Only one or the other is ever executed before continuing on with program
execution to print “done”:
Conditional statements don’t have to include an else. If
there isn’t one, Python simply does nothing if the test is false:
PYTHON
num = 53
print('before conditional...')
if num > 100:
print(num, 'is greater than 100')
print('...after conditional')OUTPUT
before conditional...
...after conditionalWe can also chain several tests together using elif,
which is short for “else if”. The following Python code uses
elif to print the sign of a number.
PYTHON
num = -3
if num > 0:
print(num, 'is positive')
elif num == 0:
print(num, 'is zero')
else:
print(num, 'is negative')OUTPUT
-3 is negativeNote that to test for equality we use a double equals sign
== rather than a single equals sign = which is
used to assign values.
We can also combine tests using and and or.
and is only true if both parts are true:
PYTHON
if (1 > 0) and (-1 >= 0):
print('both parts are true')
else:
print('at least one part is false')OUTPUT
at least one part is falsewhile or is true if at least one part is true:
OUTPUT
at least one test is trueChecking our Data
Now that we’ve seen how conditionals work, we can use them to check
for the suspicious features we saw in our inflammation data. We are
about to use functions provided by the numpy module again.
Therefore, if you’re working in a new Python session, make sure to load
the module and data with:
From the first couple of plots, we saw that maximum daily inflammation exhibits a strange behavior and raises one unit a day. Wouldn’t it be a good idea to detect such behavior and report it as suspicious? Let’s do that! However, instead of checking every single day of the study, let’s merely check if maximum inflammation in the beginning (day 0) and in the middle (day 20) of the study are equal to the corresponding day numbers.
PYTHON
max_inflammation_0 = numpy.amax(data, axis=0)[0]
max_inflammation_20 = numpy.amax(data, axis=0)[20]
if max_inflammation_0 == 0 and max_inflammation_20 == 20:
print('Suspicious looking maxima!')We also saw a different problem in the third dataset; the minima per
day were all zero (looks like a healthy person snuck into our study). We
can also check for this with an elif condition:
And if neither of these conditions are true, we can use
else to give the all-clear:
Let’s test that out:
PYTHON
data = numpy.loadtxt(fname='inflammation-01.csv', delimiter=',')
max_inflammation_0 = numpy.amax(data, axis=0)[0]
max_inflammation_20 = numpy.amax(data, axis=0)[20]
if max_inflammation_0 == 0 and max_inflammation_20 == 20:
print('Suspicious looking maxima!')
elif numpy.sum(numpy.amin(data, axis=0)) == 0:
print('Minima add up to zero!')
else:
print('Seems OK!')OUTPUT
Suspicious looking maxima!PYTHON
data = numpy.loadtxt(fname='inflammation-03.csv', delimiter=',')
max_inflammation_0 = numpy.amax(data, axis=0)[0]
max_inflammation_20 = numpy.amax(data, axis=0)[20]
if max_inflammation_0 == 0 and max_inflammation_20 == 20:
print('Suspicious looking maxima!')
elif numpy.sum(numpy.amin(data, axis=0)) == 0:
print('Minima add up to zero!')
else:
print('Seems OK!')OUTPUT
Minima add up to zero!In this way, we have asked Python to do something different depending
on the condition of our data. Here we printed messages in all cases, but
we could also imagine not using the else catch-all so that
messages are only printed when something is wrong, freeing us from
having to manually examine every plot for features we’ve seen
before.
C gets printed because the first two conditions,
4 > 5 and 4 == 5, are not true, but
4 < 5 is true. In this case only one of these conditions
can be true for at a time, but in other scenarios multiple
elif conditions could be met. In these scenarios only the
action associated with the first true elif condition will
occur, starting from the top of the conditional section. 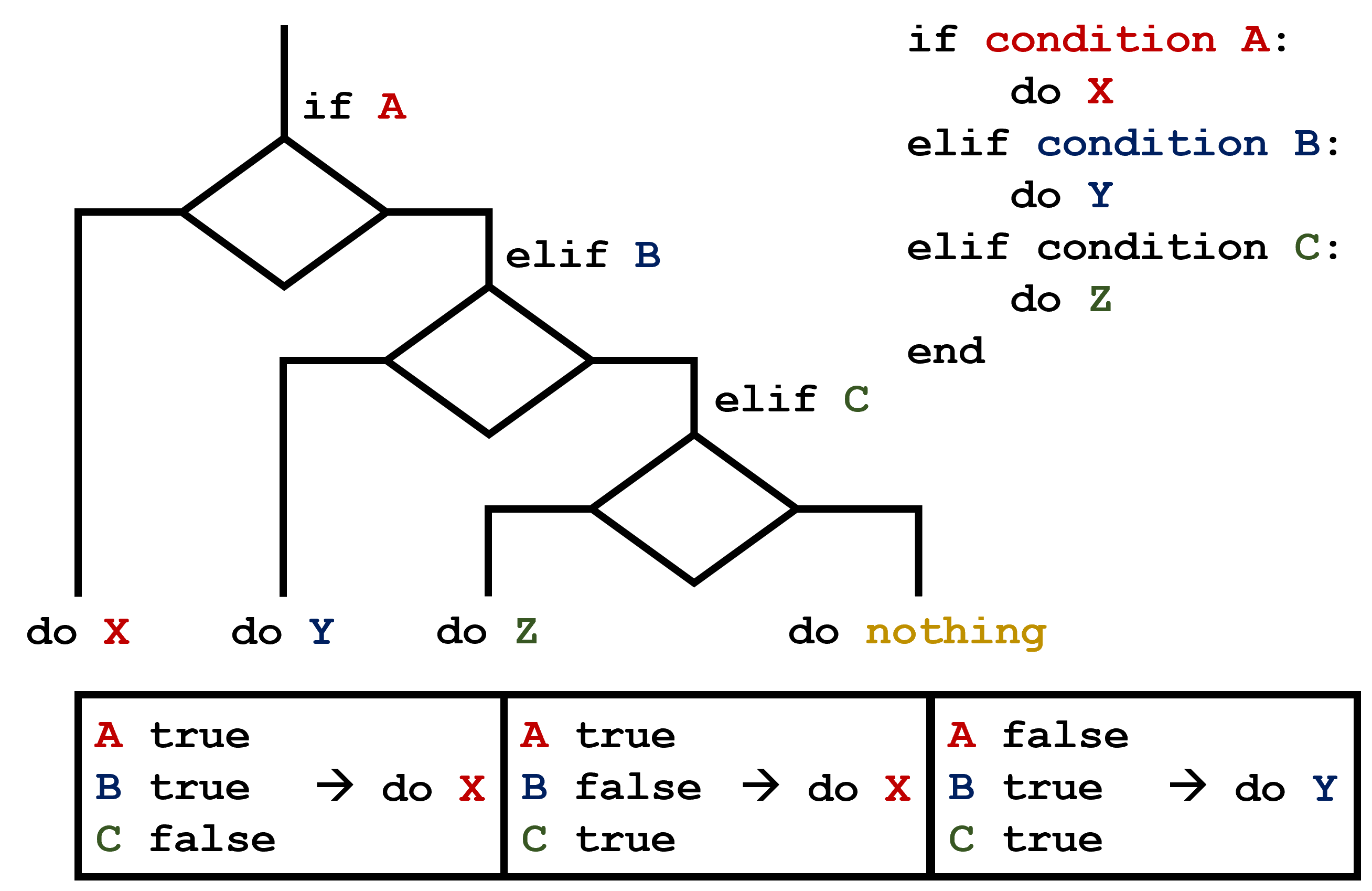 This contrasts with the case of multiple
This contrasts with the case of multiple if statements,
where every action can occur as long as their condition is met. 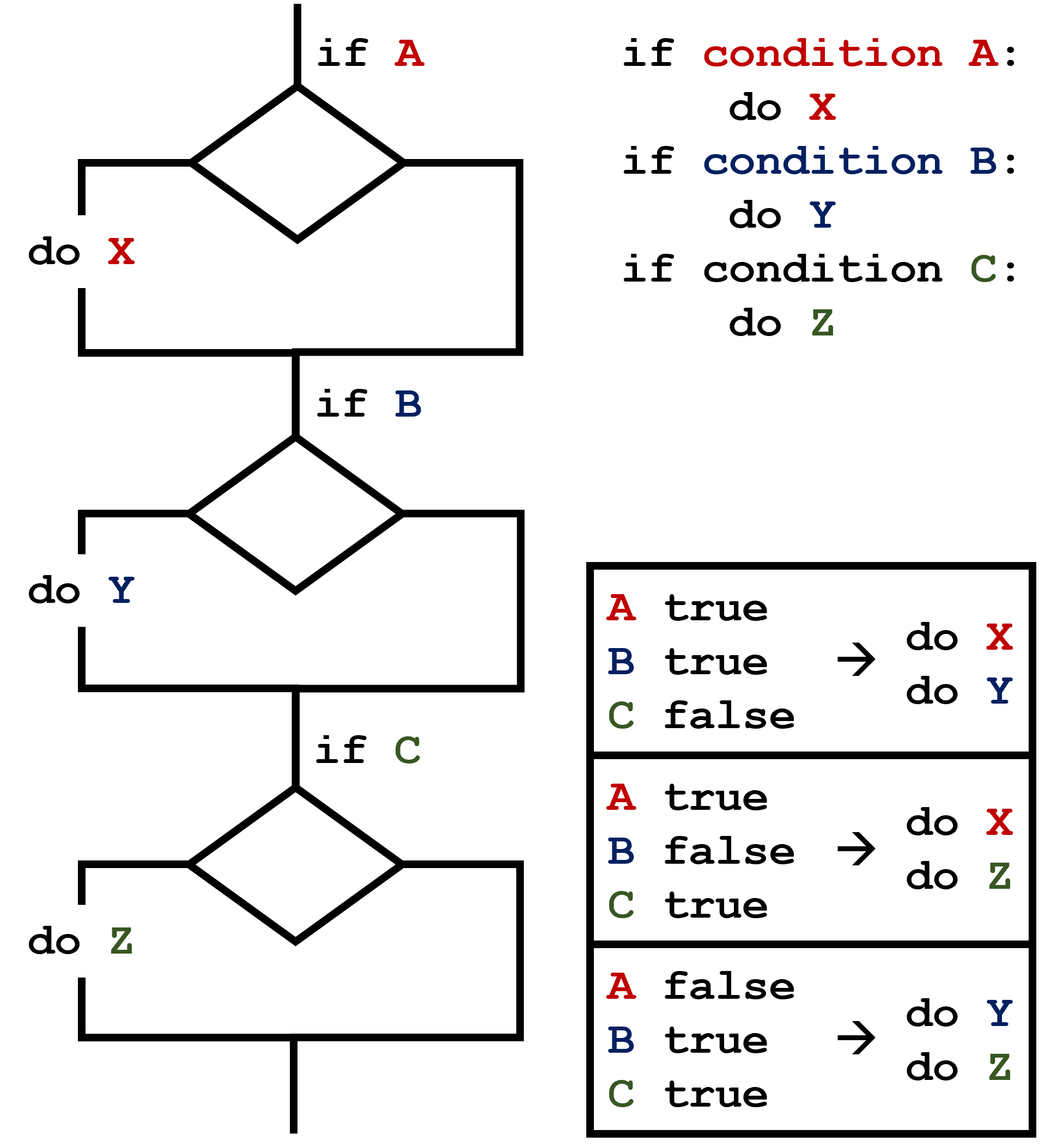
There is a built-in
function abs that returns the absolute value of a
number:
OUTPUT
12In-Place Operators
Python (and most other languages in the C family) provides in-place operators that work like this:
PYTHON
x = 1 # original value
x += 1 # add one to x, assigning result back to x
x *= 3 # multiply x by 3
print(x)OUTPUT
6Write some code that sums the positive and negative numbers in a list separately, using in-place operators. Do you think the result is more or less readable than writing the same without in-place operators?
PYTHON
positive_sum = 0
negative_sum = 0
test_list = [3, 4, 6, 1, -1, -5, 0, 7, -8]
for num in test_list:
if num > 0:
positive_sum += num
elif num == 0:
pass
else:
negative_sum += num
print(positive_sum, negative_sum)Here pass means “don’t do anything”. In this particular
case, it’s not actually needed, since if num == 0 neither
sum needs to change, but it illustrates the use of elif and
pass.
Sorting a List Into Buckets
In our data folder, large data sets are stored in files
whose names start with “inflammation-” and small data sets – in files
whose names start with “small-”. We also have some other files that we
do not care about at this point. We’d like to break all these files into
three lists called large_files, small_files,
and other_files, respectively.
Add code to the template below to do this. Note that the string
method startswith
returns True if and only if the string it is called on
starts with the string passed as an argument, that is:
OUTPUT
TrueBut
OUTPUT
FalseUse the following Python code as your starting point:
PYTHON
filenames = ['inflammation-01.csv',
'myscript.py',
'inflammation-02.csv',
'small-01.csv',
'small-02.csv']
large_files = []
small_files = []
other_files = []Your solution should:
- loop over the names of the files
- figure out which group each filename belongs in
- append the filename to that list
In the end the three lists should be:
PYTHON
for filename in filenames:
if filename.startswith('inflammation-'):
large_files.append(filename)
elif filename.startswith('small-'):
small_files.append(filename)
else:
other_files.append(filename)
print('large_files:', large_files)
print('small_files:', small_files)
print('other_files:', other_files)Counting Vowels
- Write a loop that counts the number of vowels in a character string.
- Test it on a few individual words and full sentences.
- Once you are done, compare your solution to your neighbor’s. Did you make the same decisions about how to handle the letter ‘y’ (which some people think is a vowel, and some do not)?
Key Points
- Use
if conditionto start a conditional statement,elif conditionto provide additional tests, andelseto provide a default. - The bodies of the branches of conditional statements must be indented.
- Use
==to test for equality. -
X and Yis only true if bothXandYare true. -
X or Yis true if eitherXorY, or both, are true. - Zero, the empty string, and the empty list are considered false; all other numbers, strings, and lists are considered true.
-
TrueandFalserepresent truth values.
Content from (ProgWerk) Creating Functions
Last updated on 2024-03-10 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How can I define new functions?
- What’s the difference between defining and calling a function?
- What happens when I call a function?
Objectives
- Define a function that takes parameters.
- Return a value from a function.
- Test and debug a function.
- Set default values for function parameters.
- Explain why we should divide programs into small, single-purpose functions.
At this point, we’ve seen that code can have Python make decisions about what it sees in our data. What if we want to convert some of our data, like taking a temperature in Fahrenheit and converting it to Celsius. We could write something like this for converting a single number
and for a second number we could just copy the line and rename the variables
PYTHON
fahrenheit_val = 99
celsius_val = ((fahrenheit_val - 32) * (5/9))
fahrenheit_val2 = 43
celsius_val2 = ((fahrenheit_val2 - 32) * (5/9))But we would be in trouble as soon as we had to do this more than a
couple times. Cutting and pasting it is going to make our code get very
long and very repetitive, very quickly. We’d like a way to package our
code so that it is easier to reuse, a shorthand way of re-executing
longer pieces of code. In Python we can use ‘functions’. Let’s start by
defining a function fahr_to_celsius that converts
temperatures from Fahrenheit to Celsius:
PYTHON
def explicit_fahr_to_celsius(temp):
# Assign the converted value to a variable
converted = ((temp - 32) * (5/9))
# Return the value of the new variable
return converted
def fahr_to_celsius(temp):
# Return converted value more efficiently using the return
# function without creating a new variable. This code does
# the same thing as the previous function but it is more explicit
# in explaining how the return command works.
return ((temp - 32) * (5/9))
The function definition opens with the keyword def
followed by the name of the function (fahr_to_celsius) and
a parenthesized list of parameter names (temp). The body of the function — the statements
that are executed when it runs — is indented below the definition line.
The body concludes with a return keyword followed by the
return value.
When we call the function, the values we pass to it are assigned to those variables so that we can use them inside the function. Inside the function, we use a return statement to send a result back to whoever asked for it.
Let’s try running our function.
This command should call our function, using “32” as the input and return the function value.
In fact, calling our own function is no different from calling any other function:
PYTHON
print('freezing point of water:', fahr_to_celsius(32), 'C')
print('boiling point of water:', fahr_to_celsius(212), 'C')OUTPUT
freezing point of water: 0.0 C
boiling point of water: 100.0 CWe’ve successfully called the function that we defined, and we have access to the value that we returned.
Composing Functions
Now that we’ve seen how to turn Fahrenheit into Celsius, we can also write the function to turn Celsius into Kelvin:
PYTHON
def celsius_to_kelvin(temp_c):
return temp_c + 273.15
print('freezing point of water in Kelvin:', celsius_to_kelvin(0.))OUTPUT
freezing point of water in Kelvin: 273.15What about converting Fahrenheit to Kelvin? We could write out the formula, but we don’t need to. Instead, we can compose the two functions we have already created:
PYTHON
def fahr_to_kelvin(temp_f):
temp_c = fahr_to_celsius(temp_f)
temp_k = celsius_to_kelvin(temp_c)
return temp_k
print('boiling point of water in Kelvin:', fahr_to_kelvin(212.0))OUTPUT
boiling point of water in Kelvin: 373.15This is our first taste of how larger programs are built: we define basic operations, then combine them in ever-larger chunks to get the effect we want. Real-life functions will usually be larger than the ones shown here — typically half a dozen to a few dozen lines — but they shouldn’t ever be much longer than that, or the next person who reads it won’t be able to understand what’s going on.
Variable Scope
In composing our temperature conversion functions, we created
variables inside of those functions, temp,
temp_c, temp_f, and temp_k. We
refer to these variables as local variables because they no
longer exist once the function is done executing. If we try to access
their values outside of the function, we will encounter an error:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-eed2471d229b> in <module>
----> 1 print('Again, temperature in Kelvin was:', temp_k)
NameError: name 'temp_k' is not definedIf you want to reuse the temperature in Kelvin after you have
calculated it with fahr_to_kelvin, you can store the result
of the function call in a variable:
OUTPUT
temperature in Kelvin was: 373.15The variable temp_kelvin, being defined outside any
function, is said to be global.
Inside a function, one can read the value of such global variables:
PYTHON
def print_temperatures():
print('temperature in Fahrenheit was:', temp_fahr)
print('temperature in Kelvin was:', temp_kelvin)
temp_fahr = 212.0
temp_kelvin = fahr_to_kelvin(temp_fahr)
print_temperatures()OUTPUT
temperature in Fahrenheit was: 212.0
temperature in Kelvin was: 373.15Readable functions
Consider these two functions:
PYTHON
def s(p):
a = 0
for v in p:
a += v
m = a / len(p)
d = 0
for v in p:
d += (v - m) * (v - m)
return numpy.sqrt(d / (len(p) - 1))
def std_dev(sample):
sample_sum = 0
for value in sample:
sample_sum += value
sample_mean = sample_sum / len(sample)
sum_squared_devs = 0
for value in sample:
sum_squared_devs += (value - sample_mean) * (value - sample_mean)
return numpy.sqrt(sum_squared_devs / (len(sample) - 1))The functions s and std_dev are
computationally equivalent (they both calculate the sample standard
deviation), but to a human reader, they look very different. You
probably found std_dev much easier to read and understand
than s.
As this example illustrates, both documentation and a programmer’s coding style combine to determine how easy it is for others to read and understand the programmer’s code. Choosing meaningful variable names and using blank spaces to break the code into logical “chunks” are helpful techniques for producing readable code. This is useful not only for sharing code with others, but also for the original programmer. If you need to revisit code that you wrote months ago and haven’t thought about since then, you will appreciate the value of readable code!
Combining Strings
“Adding” two strings produces their concatenation:
'a' + 'b' is 'ab'. Write a function called
fence that takes two parameters called
original and wrapper and returns a new string
that has the wrapper character at the beginning and end of the original.
A call to your function should look like this:
OUTPUT
*name*Return versus print
Note that return and print are not
interchangeable. print is a Python function that
prints data to the screen. It enables us, users, see
the data. return statement, on the other hand, makes data
visible to the program. Let’s have a look at the following function:
Question: What will we see if we execute the following commands?
Python will first execute the function add with
a = 7 and b = 3, and, therefore, print
10. However, because function add does not
have a line that starts with return (no return
“statement”), it will, by default, return nothing which, in Python
world, is called None. Therefore, A will be
assigned to None and the last line (print(A))
will print None. As a result, we will see:
OUTPUT
10
NoneSelecting Characters From Strings
If the variable s refers to a string, then
s[0] is the string’s first character and s[-1]
is its last. Write a function called outer that returns a
string made up of just the first and last characters of its input. A
call to your function should look like this:
OUTPUT
hmTesting and Documenting Your Function
Run the commands help(numpy.arange) and
help(numpy.linspace) to see how to use these functions to
generate regularly-spaced values, then use those values to test your
rescale function. Once you’ve successfully tested your
function, add a docstring that explains what it does.
PYTHON
"""Takes an array as input, and returns a corresponding array scaled so
that 0 corresponds to the minimum and 1 to the maximum value of the input array.
Examples:
>>> rescale(numpy.arange(10.0))
array([ 0. , 0.11111111, 0.22222222, 0.33333333, 0.44444444,
0.55555556, 0.66666667, 0.77777778, 0.88888889, 1. ])
>>> rescale(numpy.linspace(0, 100, 5))
array([ 0. , 0.25, 0.5 , 0.75, 1. ])
"""PYTHON
def rescale(input_array, low_val=0.0, high_val=1.0):
"""rescales input array values to lie between low_val and high_val"""
L = numpy.amin(input_array)
H = numpy.amax(input_array)
intermed_array = (input_array - L) / (H - L)
output_array = intermed_array * (high_val - low_val) + low_val
return output_arrayOUTPUT
259.81666666666666
278.15
273.15
0k is 0 because the k inside the function
f2k doesn’t know about the k defined outside
the function. When the f2k function is called, it creates a
local variable
k. The function does not return any values and does not
alter k outside of its local copy. Therefore the original
value of k remains unchanged. Beware that a local
k is created because f2k internal statements
affect a new value to it. If k was only
read, it would simply retrieve the global k
value.
Mixing Default and Non-Default Parameters
Given the following code:
PYTHON
def numbers(one, two=2, three, four=4):
n = str(one) + str(two) + str(three) + str(four)
return n
print(numbers(1, three=3))what do you expect will be printed? What is actually printed? What rule do you think Python is following?
1234one2three41239SyntaxError
Given that, what does the following piece of code display when run?
a: b: 3 c: 6a: -1 b: 3 c: 6a: -1 b: 2 c: 6a: b: -1 c: 2
Attempting to define the numbers function results in
4. SyntaxError. The defined parameters two and
four are given default values. Because one and
three are not given default values, they are required to be
included as arguments when the function is called and must be placed
before any parameters that have default values in the function
definition.
The given call to func displays
a: -1 b: 2 c: 6. -1 is assigned to the first parameter
a, 2 is assigned to the next parameter b, and
c is not passed a value, so it uses its default value
6.
Key Points
- Define a function using
def function_name(parameter). - The body of a function must be indented.
- Call a function using
function_name(value). - Numbers are stored as integers or floating-point numbers.
- Variables defined within a function can only be seen and used within the body of the function.
- Variables created outside of any function are called global variables.
- Within a function, we can access global variables.
- Variables created within a function override global variables if their names match.
- Use
help(thing)to view help for something. - Put docstrings in functions to provide help for that function.
- Specify default values for parameters when defining a function using
name=valuein the parameter list. - Parameters can be passed by matching based on name, by position, or by omitting them (in which case the default value is used).
- Put code whose parameters change frequently in a function, then call it with different parameter values to customize its behavior.
Content from (ProgWerk) Errors and Exceptions
Last updated on 2024-03-10 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How does Python report errors?
- How can I handle errors in Python programs?
Objectives
- To be able to read a traceback, and determine where the error took place and what type it is.
- To be able to describe the types of situations in which syntax errors, indentation errors, name errors, index errors, and missing file errors occur.
Every programmer encounters errors, both those who are just beginning, and those who have been programming for years. Encountering errors and exceptions can be very frustrating at times, and can make coding feel like a hopeless endeavour. However, understanding what the different types of errors are and when you are likely to encounter them can help a lot. Once you know why you get certain types of errors, they become much easier to fix.
Errors in Python have a very specific form, called a traceback. Let’s examine one:
PYTHON
# This code has an intentional error. You can type it directly or
# use it for reference to understand the error message below.
def favorite_ice_cream():
ice_creams = [
'chocolate',
'vanilla',
'strawberry'
]
print(ice_creams[3])
favorite_ice_cream()ERROR
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-1-70bd89baa4df> in <module>()
9 print(ice_creams[3])
10
----> 11 favorite_ice_cream()
<ipython-input-1-70bd89baa4df> in favorite_ice_cream()
7 'strawberry'
8 ]
----> 9 print(ice_creams[3])
10
11 favorite_ice_cream()
IndexError: list index out of rangeThis particular traceback has two levels. You can determine the number of levels by looking for the number of arrows on the left hand side. In this case:
The first shows code from the cell above, with an arrow pointing to Line 11 (which is
favorite_ice_cream()).The second shows some code in the function
favorite_ice_cream, with an arrow pointing to Line 9 (which isprint(ice_creams[3])).
The last level is the actual place where the error occurred. The
other level(s) show what function the program executed to get to the
next level down. So, in this case, the program first performed a function call to the function
favorite_ice_cream. Inside this function, the program
encountered an error on Line 6, when it tried to run the code
print(ice_creams[3]).
Long Tracebacks
Sometimes, you might see a traceback that is very long -- sometimes they might even be 20 levels deep! This can make it seem like something horrible happened, but the length of the error message does not reflect severity, rather, it indicates that your program called many functions before it encountered the error. Most of the time, the actual place where the error occurred is at the bottom-most level, so you can skip down the traceback to the bottom.
So what error did the program actually encounter? In the last line of
the traceback, Python helpfully tells us the category or type of error
(in this case, it is an IndexError) and a more detailed
error message (in this case, it says “list index out of range”).
If you encounter an error and don’t know what it means, it is still important to read the traceback closely. That way, if you fix the error, but encounter a new one, you can tell that the error changed. Additionally, sometimes knowing where the error occurred is enough to fix it, even if you don’t entirely understand the message.
If you do encounter an error you don’t recognize, try looking at the official documentation on errors. However, note that you may not always be able to find the error there, as it is possible to create custom errors. In that case, hopefully the custom error message is informative enough to help you figure out what went wrong.
Reading Error Messages
Read the Python code and the resulting traceback below, and answer the following questions:
- How many levels does the traceback have?
- What is the function name where the error occurred?
- On which line number in this function did the error occur?
- What is the type of error?
- What is the error message?
PYTHON
# This code has an intentional error. Do not type it directly;
# use it for reference to understand the error message below.
def print_message(day):
messages = [
'Hello, world!',
'Today is Tuesday!',
'It is the middle of the week.',
'Today is Donnerstag in German!',
'Last day of the week!',
'Hooray for the weekend!',
'Aw, the weekend is almost over.'
]
print(messages[day])
def print_sunday_message():
print_message(7)
print_sunday_message()ERROR
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-3ad455d81842> in <module>
16 print_message(7)
17
---> 18 print_sunday_message()
19
<ipython-input-7-3ad455d81842> in print_sunday_message()
14
15 def print_sunday_message():
---> 16 print_message(7)
17
18 print_sunday_message()
<ipython-input-7-3ad455d81842> in print_message(day)
11 'Aw, the weekend is almost over.'
12 ]
---> 13 print(messages[day])
14
15 def print_sunday_message():
IndexError: list index out of range- 3 levels
print_message- 13
IndexError-
list index out of rangeYou can then infer that7is not the right index to use withmessages.
Syntax Errors
When you forget a colon at the end of a line, accidentally add one
space too many when indenting under an if statement, or
forget a parenthesis, you will encounter a syntax error. This means that
Python couldn’t figure out how to read your program. This is similar to
forgetting punctuation in English: for example, this text is difficult
to read there is no punctuation there is also no capitalization why is
this hard because you have to figure out where each sentence ends you
also have to figure out where each sentence begins to some extent it
might be ambiguous if there should be a sentence break or not
People can typically figure out what is meant by text with no punctuation, but people are much smarter than computers. If Python doesn’t know how to read the program, it will give up and inform you with an error. For example:
ERROR
File "<ipython-input-3-6bb841ea1423>", line 1
def some_function()
^
SyntaxError: invalid syntaxHere, Python tells us that there is a SyntaxError on
line 1, and even puts a little arrow in the place where there is an
issue. In this case the problem is that the function definition is
missing a colon at the end.
Actually, the function above has two issues with syntax. If
we fix the problem with the colon, we see that there is also an
IndentationError, which means that the lines in the
function definition do not all have the same indentation:
ERROR
File "<ipython-input-4-ae290e7659cb>", line 4
return msg
^
IndentationError: unexpected indentBoth SyntaxError and IndentationError
indicate a problem with the syntax of your program, but an
IndentationError is more specific: it always means
that there is a problem with how your code is indented.
Tabs and Spaces
Some indentation errors are harder to spot than others. In
particular, mixing spaces and tabs can be difficult to spot because they
are both whitespace. In the
example below, the first two lines in the body of the function
some_function are indented with tabs, while the third line
— with spaces. If you’re working in a Jupyter notebook, be sure to copy
and paste this example rather than trying to type it in manually because
Jupyter automatically replaces tabs with spaces.
Visually it is impossible to spot the error. Fortunately, Python does not allow you to mix tabs and spaces.
ERROR
File "<ipython-input-5-653b36fbcd41>", line 4
return msg
^
TabError: inconsistent use of tabs and spaces in indentationVariable Name Errors
Another very common type of error is called a NameError,
and occurs when you try to use a variable that does not exist. For
example:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-7-9d7b17ad5387> in <module>()
----> 1 print(a)
NameError: name 'a' is not definedVariable name errors come with some of the most informative error messages, which are usually of the form “name ‘the_variable_name’ is not defined”.
Why does this error message occur? That’s a harder question to answer, because it depends on what your code is supposed to do. However, there are a few very common reasons why you might have an undefined variable. The first is that you meant to use a string, but forgot to put quotes around it:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-8-9553ee03b645> in <module>()
----> 1 print(hello)
NameError: name 'hello' is not definedThe second reason is that you might be trying to use a variable that
does not yet exist. In the following example, count should
have been defined (e.g., with count = 0) before the for
loop:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-9-dd6a12d7ca5c> in <module>()
1 for number in range(10):
----> 2 count = count + number
3 print('The count is:', count)
NameError: name 'count' is not definedFinally, the third possibility is that you made a typo when you were
writing your code. Let’s say we fixed the error above by adding the line
Count = 0 before the for loop. Frustratingly, this actually
does not fix the error. Remember that variables are case-sensitive, so the variable
count is different from Count. We still get
the same error, because we still have not defined
count:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-10-d77d40059aea> in <module>()
1 Count = 0
2 for number in range(10):
----> 3 count = count + number
4 print('The count is:', count)
NameError: name 'count' is not definedIndex Errors
Next up are errors having to do with containers (like lists and strings) and the items within them. If you try to access an item in a list or a string that does not exist, then you will get an error. This makes sense: if you asked someone what day they would like to get coffee, and they answered “caturday”, you might be a bit annoyed. Python gets similarly annoyed if you try to ask it for an item that doesn’t exist:
PYTHON
letters = ['a', 'b', 'c']
print('Letter #1 is', letters[0])
print('Letter #2 is', letters[1])
print('Letter #3 is', letters[2])
print('Letter #4 is', letters[3])OUTPUT
Letter #1 is a
Letter #2 is b
Letter #3 is cERROR
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-11-d817f55b7d6c> in <module>()
3 print('Letter #2 is', letters[1])
4 print('Letter #3 is', letters[2])
----> 5 print('Letter #4 is', letters[3])
IndexError: list index out of rangeHere, Python is telling us that there is an IndexError
in our code, meaning we tried to access a list index that did not
exist.
File Errors
The last type of error we’ll cover today are those associated with
reading and writing files: FileNotFoundError. If you try to
read a file that does not exist, you will receive a
FileNotFoundError telling you so. If you attempt to write
to a file that was opened read-only, Python 3 returns an
UnsupportedOperationError. More generally, problems with
input and output manifest as OSErrors, which may show up as
a more specific subclass; you can see the
list in the Python docs. They all have a unique UNIX
errno, which is you can see in the error message.
ERROR
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-14-f6e1ac4aee96> in <module>()
----> 1 file_handle = open('myfile.txt', 'r')
FileNotFoundError: [Errno 2] No such file or directory: 'myfile.txt'One reason for receiving this error is that you specified an
incorrect path to the file. For example, if I am currently in a folder
called myproject, and I have a file in
myproject/writing/myfile.txt, but I try to open
myfile.txt, this will fail. The correct path would be
writing/myfile.txt. It is also possible that the file name
or its path contains a typo.
A related issue can occur if you use the “read” flag instead of the
“write” flag. Python will not give you an error if you try to open a
file for writing when the file does not exist. However, if you meant to
open a file for reading, but accidentally opened it for writing, and
then try to read from it, you will get an
UnsupportedOperation error telling you that the file was
not opened for reading:
ERROR
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-15-b846479bc61f> in <module>()
1 file_handle = open('myfile.txt', 'w')
----> 2 file_handle.read()
UnsupportedOperation: not readableThese are the most common errors with files, though many others exist. If you get an error that you’ve never seen before, searching the Internet for that error type often reveals common reasons why you might get that error.
Identifying Variable Name Errors
- Read the code below, and (without running it) try to identify what the errors are.
- Run the code, and read the error message. What type of
NameErrordo you think this is? In other words, is it a string with no quotes, a misspelled variable, or a variable that should have been defined but was not? - Fix the error.
- Repeat steps 2 and 3, until you have fixed all the errors.
3 NameErrors for number being misspelled,
for message not defined, and for a not being
in quotes.
Fixed version:
Key Points
- Tracebacks can look intimidating, but they give us a lot of useful information about what went wrong in our program, including where the error occurred and what type of error it was.
- An error having to do with the ‘grammar’ or syntax of the program is
called a
SyntaxError. If the issue has to do with how the code is indented, then it will be called anIndentationError. - A
NameErrorwill occur when trying to use a variable that does not exist. Possible causes are that a variable definition is missing, a variable reference differs from its definition in spelling or capitalization, or the code contains a string that is missing quotes around it. - Containers like lists and strings will generate errors if you try to
access items in them that do not exist. This type of error is called an
IndexError. - Trying to read a file that does not exist will give you an
FileNotFoundError. Trying to read a file that is open for writing, or writing to a file that is open for reading, will give you anIOError.
Content from (ProgWerk) Defensive Programming
Last updated on 2024-03-10 | Edit this page
Estimated time: 40 minutes
Overview
Questions
- How can I make my programs more reliable?
Objectives
- Explain what an assertion is.
- Add assertions that check the program’s state is correct.
- Correctly add precondition and postcondition assertions to functions.
- Explain what test-driven development is, and use it when creating new functions.
- Explain why variables should be initialized using actual data values rather than arbitrary constants.
Our previous lessons have introduced the basic tools of programming: variables and lists, file I/O, loops, conditionals, and functions. What they haven’t done is show us how to tell whether a program is getting the right answer, and how to tell if it’s still getting the right answer as we make changes to it.
To achieve that, we need to:
- Write programs that check their own operation.
- Write and run tests for widely-used functions.
- Make sure we know what “correct” actually means.
The good news is, doing these things will speed up our programming, not slow it down. As in real carpentry — the kind done with lumber — the time saved by measuring carefully before cutting a piece of wood is much greater than the time that measuring takes.
Assertions
The first step toward getting the right answers from our programs is to assume that mistakes will happen and to guard against them. This is called defensive programming, and the most common way to do it is to add assertions to our code so that it checks itself as it runs. An assertion is simply a statement that something must be true at a certain point in a program. When Python sees one, it evaluates the assertion’s condition. If it’s true, Python does nothing, but if it’s false, Python halts the program immediately and prints the error message if one is provided. For example, this piece of code halts as soon as the loop encounters a value that isn’t positive:
PYTHON
numbers = [1.5, 2.3, 0.7, -0.001, 4.4]
total = 0.0
for num in numbers:
assert num > 0.0, 'Data should only contain positive values'
total += num
print('total is:', total)ERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-19-33d87ea29ae4> in <module>()
2 total = 0.0
3 for num in numbers:
----> 4 assert num > 0.0, 'Data should only contain positive values'
5 total += num
6 print('total is:', total)
AssertionError: Data should only contain positive valuesPrograms like the Firefox browser are full of assertions: 10-20% of the code they contain are there to check that the other 80–90% are working correctly. Broadly speaking, assertions fall into three categories:
A precondition is something that must be true at the start of a function in order for it to work correctly.
A postcondition is something that the function guarantees is true when it finishes.
An invariant is something that is always true at a particular point inside a piece of code.
For example, suppose we are representing rectangles using a tuple of four coordinates
(x0, y0, x1, y1), representing the lower left and upper
right corners of the rectangle. In order to do some calculations, we
need to normalize the rectangle so that the lower left corner is at the
origin and the longest side is 1.0 units long. This function does that,
but checks that its input is correctly formatted and that its result
makes sense:
PYTHON
def normalize_rectangle(rect):
"""Normalizes a rectangle so that it is at the origin and 1.0 units long on its longest axis.
Input should be of the format (x0, y0, x1, y1).
(x0, y0) and (x1, y1) define the lower left and upper right corners
of the rectangle, respectively."""
assert len(rect) == 4, 'Rectangles must contain 4 coordinates'
x0, y0, x1, y1 = rect
assert x0 < x1, 'Invalid X coordinates'
assert y0 < y1, 'Invalid Y coordinates'
dx = x1 - x0
dy = y1 - y0
if dx > dy:
scaled = dx / dy
upper_x, upper_y = 1.0, scaled
else:
scaled = dx / dy
upper_x, upper_y = scaled, 1.0
assert 0 < upper_x <= 1.0, 'Calculated upper X coordinate invalid'
assert 0 < upper_y <= 1.0, 'Calculated upper Y coordinate invalid'
return (0, 0, upper_x, upper_y)The preconditions on lines 6, 8, and 9 catch invalid inputs:
ERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-2-1b9cd8e18a1f> in <module>
----> 1 print(normalize_rectangle( (0.0, 1.0, 2.0) )) # missing the fourth coordinate
<ipython-input-1-c94cf5b065b9> in normalize_rectangle(rect)
4 (x0, y0) and (x1, y1) define the lower left and upper right corners
5 of the rectangle, respectively."""
----> 6 assert len(rect) == 4, 'Rectangles must contain 4 coordinates'
7 x0, y0, x1, y1 = rect
8 assert x0 < x1, 'Invalid X coordinates'
AssertionError: Rectangles must contain 4 coordinatesERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-3-325036405532> in <module>
----> 1 print(normalize_rectangle( (4.0, 2.0, 1.0, 5.0) )) # X axis inverted
<ipython-input-1-c94cf5b065b9> in normalize_rectangle(rect)
6 assert len(rect) == 4, 'Rectangles must contain 4 coordinates'
7 x0, y0, x1, y1 = rect
----> 8 assert x0 < x1, 'Invalid X coordinates'
9 assert y0 < y1, 'Invalid Y coordinates'
10
AssertionError: Invalid X coordinatesThe post-conditions on lines 20 and 21 help us catch bugs by telling us when our calculations might have been incorrect. For example, if we normalize a rectangle that is taller than it is wide everything seems OK:
OUTPUT
(0, 0, 0.2, 1.0)but if we normalize one that’s wider than it is tall, the assertion is triggered:
ERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-5-8d4a48f1d068> in <module>
----> 1 print(normalize_rectangle( (0.0, 0.0, 5.0, 1.0) ))
<ipython-input-1-c94cf5b065b9> in normalize_rectangle(rect)
19
20 assert 0 < upper_x <= 1.0, 'Calculated upper X coordinate invalid'
---> 21 assert 0 < upper_y <= 1.0, 'Calculated upper Y coordinate invalid'
22
23 return (0, 0, upper_x, upper_y)
AssertionError: Calculated upper Y coordinate invalidRe-reading our function, we realize that line 14 should divide
dy by dx rather than dx by
dy. In a Jupyter notebook, you can display line numbers by
typing Ctrl+M followed by L. If we had
left out the assertion at the end of the function, we would have created
and returned something that had the right shape as a valid answer, but
wasn’t. Detecting and debugging that would almost certainly have taken
more time in the long run than writing the assertion.
But assertions aren’t just about catching errors: they also help people understand programs. Each assertion gives the person reading the program a chance to check (consciously or otherwise) that their understanding matches what the code is doing.
Most good programmers follow two rules when adding assertions to their code. The first is, fail early, fail often. The greater the distance between when and where an error occurs and when it’s noticed, the harder the error will be to debug, so good code catches mistakes as early as possible.
The second rule is, turn bugs into assertions or tests. Whenever you fix a bug, write an assertion that catches the mistake should you make it again. If you made a mistake in a piece of code, the odds are good that you have made other mistakes nearby, or will make the same mistake (or a related one) the next time you change it. Writing assertions to check that you haven’t regressed (i.e., haven’t re-introduced an old problem) can save a lot of time in the long run, and helps to warn people who are reading the code (including your future self) that this bit is tricky.
Test-Driven Development
An assertion checks that something is true at a particular point in the program. The next step is to check the overall behavior of a piece of code, i.e., to make sure that it produces the right output when it’s given a particular input. For example, suppose we need to find where two or more time series overlap. The range of each time series is represented as a pair of numbers, which are the time the interval started and ended. The output is the largest range that they all include:

Most novice programmers would solve this problem like this:
- Write a function
range_overlap. - Call it interactively on two or three different inputs.
- If it produces the wrong answer, fix the function and re-run that test.
This clearly works — after all, thousands of scientists are doing it right now — but there’s a better way:
- Write a short function for each test.
- Write a
range_overlapfunction that should pass those tests. - If
range_overlapproduces any wrong answers, fix it and re-run the test functions.
Writing the tests before writing the function they exercise is called test-driven development (TDD). Its advocates believe it produces better code faster because:
- If people write tests after writing the thing to be tested, they are subject to confirmation bias, i.e., they subconsciously write tests to show that their code is correct, rather than to find errors.
- Writing tests helps programmers figure out what the function is actually supposed to do.
We start by defining an empty function
range_overlap:
Here are three test statements for range_overlap:
PYTHON
assert range_overlap([ (0.0, 1.0) ]) == (0.0, 1.0)
assert range_overlap([ (2.0, 3.0), (2.0, 4.0) ]) == (2.0, 3.0)
assert range_overlap([ (0.0, 1.0), (0.0, 2.0), (-1.0, 1.0) ]) == (0.0, 1.0)ERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-25-d8be150fbef6> in <module>()
----> 1 assert range_overlap([ (0.0, 1.0) ]) == (0.0, 1.0)
2 assert range_overlap([ (2.0, 3.0), (2.0, 4.0) ]) == (2.0, 3.0)
3 assert range_overlap([ (0.0, 1.0), (0.0, 2.0), (-1.0, 1.0) ]) == (0.0, 1.0)
AssertionError:The error is actually reassuring: we haven’t implemented any logic
into range_overlap yet, so if the tests passed, it would
indicate that we’ve written an entirely ineffective test.
And as a bonus of writing these tests, we’ve implicitly defined what our input and output look like: we expect a list of pairs as input, and produce a single pair as output.
Something important is missing, though. We don’t have any tests for the case where the ranges don’t overlap at all:
What should range_overlap do in this case: fail with an
error message, produce a special value like (0.0, 0.0) to
signal that there’s no overlap, or something else? Any actual
implementation of the function will do one of these things; writing the
tests first helps us figure out which is best before we’re
emotionally invested in whatever we happened to write before we realized
there was an issue.
And what about this case?
Do two segments that touch at their endpoints overlap or not?
Mathematicians usually say “yes”, but engineers usually say “no”. The
best answer is “whatever is most useful in the rest of our program”, but
again, any actual implementation of range_overlap is going
to do something, and whatever it is ought to be consistent with
what it does when there’s no overlap at all.
Since we’re planning to use the range this function returns as the X axis in a time series chart, we decide that:
- every overlap has to have non-zero width, and
- we will return the special value
Nonewhen there’s no overlap.
None is built into Python, and means “nothing here”.
(Other languages often call the equivalent value null or
nil). With that decision made, we can finish writing our
last two tests:
PYTHON
assert range_overlap([ (0.0, 1.0), (5.0, 6.0) ]) == None
assert range_overlap([ (0.0, 1.0), (1.0, 2.0) ]) == NoneERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-26-d877ef460ba2> in <module>()
----> 1 assert range_overlap([ (0.0, 1.0), (5.0, 6.0) ]) == None
2 assert range_overlap([ (0.0, 1.0), (1.0, 2.0) ]) == None
AssertionError:Again, we get an error because we haven’t written our function, but we’re now ready to do so:
PYTHON
def range_overlap(ranges):
"""Return common overlap among a set of [left, right] ranges."""
max_left = 0.0
min_right = 1.0
for (left, right) in ranges:
max_left = max(max_left, left)
min_right = min(min_right, right)
return (max_left, min_right)Take a moment to think about why we calculate the left endpoint of the overlap as the maximum of the input left endpoints, and the overlap right endpoint as the minimum of the input right endpoints. We’d now like to re-run our tests, but they’re scattered across three different cells. To make running them easier, let’s put them all in a function:
PYTHON
def test_range_overlap():
assert range_overlap([ (0.0, 1.0), (5.0, 6.0) ]) == None
assert range_overlap([ (0.0, 1.0), (1.0, 2.0) ]) == None
assert range_overlap([ (0.0, 1.0) ]) == (0.0, 1.0)
assert range_overlap([ (2.0, 3.0), (2.0, 4.0) ]) == (2.0, 3.0)
assert range_overlap([ (0.0, 1.0), (0.0, 2.0), (-1.0, 1.0) ]) == (0.0, 1.0)
assert range_overlap([]) == NoneWe can now test range_overlap with a single function
call:
ERROR
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-29-cf9215c96457> in <module>()
----> 1 test_range_overlap()
<ipython-input-28-5d4cd6fd41d9> in test_range_overlap()
1 def test_range_overlap():
----> 2 assert range_overlap([ (0.0, 1.0), (5.0, 6.0) ]) == None
3 assert range_overlap([ (0.0, 1.0), (1.0, 2.0) ]) == None
4 assert range_overlap([ (0.0, 1.0) ]) == (0.0, 1.0)
5 assert range_overlap([ (2.0, 3.0), (2.0, 4.0) ]) == (2.0, 3.0)
AssertionError:The first test that was supposed to produce None fails,
so we know something is wrong with our function. We don’t know
whether the other tests passed or failed because Python halted the
program as soon as it spotted the first error. Still, some information
is better than none, and if we trace the behavior of the function with
that input, we realize that we’re initializing max_left and
min_right to 0.0 and 1.0 respectively, regardless of the
input values. This violates another important rule of programming:
always initialize from data.
Pre- and Post-Conditions
Suppose you are writing a function called average that
calculates the average of the numbers in a NumPy array. What
pre-conditions and post-conditions would you write for it? Compare your
answer to your neighbor’s: can you think of a function that will pass
your tests but not his/hers or vice versa?
Testing Assertions
Given a sequence of a number of cars, the function
get_total_cars returns the total number of cars.
OUTPUT
10OUTPUT
ValueError: invalid literal for int() with base 10: 'a'Explain in words what the assertions in this function check, and for each one, give an example of input that will make that assertion fail.
- The first assertion checks that the input sequence
valuesis not empty. An empty sequence such as[]will make it fail. - The second assertion checks that each value in the list can be
turned into an integer. Input such as
[1, 2, 'c', 3]will make it fail. - The third assertion checks that the total of the list is greater
than 0. Input such as
[-10, 2, 3]will make it fail.
Key Points
- Program defensively, i.e., assume that errors are going to arise, and write code to detect them when they do.
- Put assertions in programs to check their state as they run, and to help readers understand how those programs are supposed to work.
- Use preconditions to check that the inputs to a function are safe to use.
- Use postconditions to check that the output from a function is safe to use.
- Write tests before writing code in order to help determine exactly what that code is supposed to do.
Content from (ProgWerk) Debugging
Last updated on 2024-03-11 | Edit this page
Estimated time: 50 minutes
Overview
Questions
- How can I debug my program?
Objectives
- Debug code containing an error systematically.
- Identify ways of making code less error-prone and more easily tested.
Once testing has uncovered problems, the next step is to fix them. Many novices do this by making more-or-less random changes to their code until it seems to produce the right answer, but that’s very inefficient (and the result is usually only correct for the one case they’re testing). The more experienced a programmer is, the more systematically they debug, and most follow some variation on the rules explained below.
Know What It’s Supposed to Do
The first step in debugging something is to know what it’s supposed to do. “My program doesn’t work” isn’t good enough: in order to diagnose and fix problems, we need to be able to tell correct output from incorrect. If we can write a test case for the failing case — i.e., if we can assert that with these inputs, the function should produce that result — then we’re ready to start debugging. If we can’t, then we need to figure out how we’re going to know when we’ve fixed things.
But writing test cases for scientific software is frequently harder than writing test cases for commercial applications, because if we knew what the output of the scientific code was supposed to be, we wouldn’t be running the software: we’d be writing up our results and moving on to the next program. In practice, scientists tend to do the following:
Test with simplified data. Before doing statistics on a real data set, we should try calculating statistics for a single record, for two identical records, for two records whose values are one step apart, or for some other case where we can calculate the right answer by hand.
Test a simplified case. If our program is supposed to simulate magnetic eddies in rapidly-rotating blobs of supercooled helium, our first test should be a blob of helium that isn’t rotating, and isn’t being subjected to any external electromagnetic fields. Similarly, if we’re looking at the effects of climate change on speciation, our first test should hold temperature, precipitation, and other factors constant.
Compare to an oracle. A test oracle is something whose results are trusted, such as experimental data, an older program, or a human expert. We use test oracles to determine if our new program produces the correct results. If we have a test oracle, we should store its output for particular cases so that we can compare it with our new results as often as we like without re-running that program.
Check conservation laws. Mass, energy, and other quantities are conserved in physical systems, so they should be in programs as well. Similarly, if we are analyzing patient data, the number of records should either stay the same or decrease as we move from one analysis to the next (since we might throw away outliers or records with missing values). If “new” patients start appearing out of nowhere as we move through our pipeline, it’s probably a sign that something is wrong.
Visualize. Data analysts frequently use simple visualizations to check both the science they’re doing and the correctness of their code. This should only be used for debugging as a last resort, though, since it’s very hard to compare two visualizations automatically.
Make It Fail Every Time
We can only debug something when it fails, so the second step is always to find a test case that makes it fail every time. The “every time” part is important because few things are more frustrating than debugging an intermittent problem: if we have to call a function a dozen times to get a single failure, the odds are good that we’ll scroll past the failure when it actually occurs.
As part of this, it’s always important to check that our code is “plugged in”, i.e., that we’re actually exercising the problem that we think we are. Every programmer has spent hours chasing a bug, only to realize that they were actually calling their code on the wrong data set or with the wrong configuration parameters, or are using the wrong version of the software entirely. Mistakes like these are particularly likely to happen when we’re tired, frustrated, and up against a deadline, which is one of the reasons late-night (or overnight) coding sessions are almost never worthwhile.
Make It Fail Fast
If it takes 20 minutes for the bug to surface, we can only do three experiments an hour. This means that we’ll get less data in more time and that we’re more likely to be distracted by other things as we wait for our program to fail, which means the time we are spending on the problem is less focused. It’s therefore critical to make it fail fast.
As well as making the program fail fast in time, we want to make it fail fast in space, i.e., we want to localize the failure to the smallest possible region of code:
The smaller the gap between cause and effect, the easier the connection is to find. Many programmers therefore use a divide and conquer strategy to find bugs, i.e., if the output of a function is wrong, they check whether things are OK in the middle, then concentrate on either the first or second half, and so on.
N things can interact in N! different ways, so every line of code that isn’t run as part of a test means more than one thing we don’t need to worry about.
Change One Thing at a Time, For a Reason
Replacing random chunks of code is unlikely to do much good. (After all, if you got it wrong the first time, you’ll probably get it wrong the second and third as well.) Good programmers therefore change one thing at a time, for a reason. They are either trying to gather more information (“is the bug still there if we change the order of the loops?”) or test a fix (“can we make the bug go away by sorting our data before processing it?”).
Every time we make a change, however small, we should re-run our tests immediately, because the more things we change at once, the harder it is to know what’s responsible for what (those N! interactions again). And we should re-run all of our tests: more than half of fixes made to code introduce (or re-introduce) bugs, so re-running all of our tests tells us whether we have regressed.
Keep Track of What You’ve Done
Good scientists keep track of what they’ve done so that they can reproduce their work, and so that they don’t waste time repeating the same experiments or running ones whose results won’t be interesting. Similarly, debugging works best when we keep track of what we’ve done and how well it worked. If we find ourselves asking, “Did left followed by right with an odd number of lines cause the crash? Or was it right followed by left? Or was I using an even number of lines?” then it’s time to step away from the computer, take a deep breath, and start working more systematically.
Records are particularly useful when the time comes to ask for help. People are more likely to listen to us when we can explain clearly what we did, and we’re better able to give them the information they need to be useful.
Version Control Revisited
Version control is often used to reset software to a known state during debugging, and to explore recent changes to code that might be responsible for bugs. In particular, most version control systems (e.g. git, Mercurial) have:
- a
blamecommand that shows who last changed each line of a file; - a
bisectcommand that helps with finding the commit that introduced an issue.
Be Humble
And speaking of help: if we can’t find a bug in 10 minutes, we should be humble and ask for help. Explaining the problem to someone else is often useful, since hearing what we’re thinking helps us spot inconsistencies and hidden assumptions. If you don’t have someone nearby to share your problem description with, get a rubber duck!
Asking for help also helps alleviate confirmation bias. If we have just spent an hour writing a complicated program, we want it to work, so we’re likely to keep telling ourselves why it should, rather than searching for the reason it doesn’t. People who aren’t emotionally invested in the code can be more objective, which is why they’re often able to spot the simple mistakes we have overlooked.
Part of being humble is learning from our mistakes. Programmers tend to get the same things wrong over and over: either they don’t understand the language and libraries they’re working with, or their model of how things work is wrong. In either case, taking note of why the error occurred and checking for it next time quickly turns into not making the mistake at all.
And that is what makes us most productive in the long run. As the saying goes, A week of hard work can sometimes save you an hour of thought. If we train ourselves to avoid making some kinds of mistakes, to break our code into modular, testable chunks, and to turn every assumption (or mistake) into an assertion, it will actually take us less time to produce working programs, not more.
Debug With a Neighbor
Take a function that you have written today, and introduce a tricky bug. Your function should still run, but will give the wrong output. Switch seats with your neighbor and attempt to debug the bug that they introduced into their function. Which of the principles discussed above did you find helpful?
Not Supposed to be the Same
You are assisting a researcher with Python code that computes the Body Mass Index (BMI) of patients. The researcher is concerned because all patients seemingly have unusual and identical BMIs, despite having different physiques. BMI is calculated as weight in kilograms divided by the square of height in metres.
Use the debugging principles in this exercise and locate problems with the code. What suggestions would you give the researcher for ensuring any later changes they make work correctly? What bugs do you spot?
PYTHON
patients = [[70, 1.8], [80, 1.9], [150, 1.7]]
def calculate_bmi(weight, height):
return weight / (height ** 2)
for patient in patients:
weight, height = patients[0]
bmi = calculate_bmi(height, weight)
print("Patient's BMI is:", bmi)OUTPUT
Patient's BMI is: 0.000367
Patient's BMI is: 0.000367
Patient's BMI is: 0.000367Suggestions for debugging
- Add printing statement in the
calculate_bmifunction, likeprint('weight:', weight, 'height:', height), to make clear that what the BMI is based on. - Change
print("Patient's BMI is: %f" % bmi)toprint("Patient's BMI (weight: %f, height: %f) is: %f" % (weight, height, bmi)), in order to be able to distinguish bugs in the function from bugs in the loop.
Content from (ProgWerk) Command-Line Programs
Last updated on 2024-03-11 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How can I write Python programs that will work like Unix command-line tools?
Objectives
- Use the values of command-line arguments in a program.
- Handle flags and files separately in a command-line program.
- Read data from standard input in a program so that it can be used in a pipeline.
The Jupyter Notebook and other interactive tools are great for prototyping code and exploring data, but sooner or later we will want to use our program in a pipeline or run it in a shell script to process thousands of data files. In order to do that in an efficient way, we need to make our programs work like other Unix command-line tools. For example, we may want a program that reads a dataset and prints the average inflammation per patient.
This program does exactly what we want - it prints the average inflammation per patient for a given file.
OUTPUT
5.45
5.425
6.1
...
6.4
7.05
5.9We might also want to look at the minimum of the first four lines
or the maximum inflammations in several files one after another:
Our scripts should do the following:
- If no filename is given on the command line, read data from standard input.
- If one or more filenames are given, read data from them and report statistics for each file separately.
- Use the
--min,--mean, or--maxflag to determine what statistic to print.
To make this work, we need to know how to handle command-line arguments in a program, and understand how to handle standard input. We’ll tackle these questions in turn below.
Command-Line Arguments
We are going to create a file with our python code in, then use the
bash shell to run the code. Using the text editor of your choice, save
the following in a text file called sys_version.py:
The first line imports a library called sys, which is
short for “system”. It defines values such as sys.version,
which describes which version of Python we are running. We can run this
script from the command line like this:
OUTPUT
version is 3.4.3+ (default, Jul 28 2015, 13:17:50)
[GCC 4.9.3]Create another file called argv_list.py and save the
following text to it.
The strange name argv stands for “argument values”.
Whenever Python runs a program, it takes all of the values given on the
command line and puts them in the list sys.argv so that the
program can determine what they were. If we run this program with no
arguments:
OUTPUT
sys.argv is ['argv_list.py']the only thing in the list is the full path to our script, which is
always sys.argv[0]. If we run it with a few arguments,
however:
OUTPUT
sys.argv is ['argv_list.py', 'first', 'second', 'third']then Python adds each of those arguments to that magic list.
With this in hand, let’s build a version of readings.py
that always prints the per-patient mean of a single data file. The first
step is to write a function that outlines our implementation, and a
placeholder for the function that does the actual work. By convention
this function is usually called main, though we can call it
whatever we want:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
filename = sys.argv[1]
data = numpy.loadtxt(filename, delimiter=',')
for row_mean in numpy.mean(data, axis=1):
print(row_mean)This function gets the name of the script from
sys.argv[0], because that’s where it’s always put, and the
name of the file to process from sys.argv[1]. Here’s a
simple test:
There is no output because we have defined a function, but haven’t
actually called it. Let’s add a call to main:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
filename = sys.argv[1]
data = numpy.loadtxt(filename, delimiter=',')
for row_mean in numpy.mean(data, axis=1):
print(row_mean)
if __name__ == '__main__':
main()and run that:
OUTPUT
5.45
5.425
6.1
5.9
5.55
6.225
5.975
6.65
6.625
6.525
6.775
5.8
6.225
5.75
5.225
6.3
6.55
5.7
5.85
6.55
5.775
5.825
6.175
6.1
5.8
6.425
6.05
6.025
6.175
6.55
6.175
6.35
6.725
6.125
7.075
5.725
5.925
6.15
6.075
5.75
5.975
5.725
6.3
5.9
6.75
5.925
7.225
6.15
5.95
6.275
5.7
6.1
6.825
5.975
6.725
5.7
6.25
6.4
7.05
5.9Running Versus Importing
Running a Python script in bash is very similar to importing that file in Python. The biggest difference is that we don’t expect anything to happen when we import a file, whereas when running a script, we expect to see some output printed to the console.
In order for a Python script to work as expected when imported or when run as a script, we typically put the part of the script that produces output in the following if statement:
When you import a Python file, __name__ is the name of
that file (e.g., when importing readings.py,
__name__ is 'readings'). However, when running
a script in bash, __name__ is always set to
'__main__' in that script so that you can determine if the
file is being imported or run as a script.
The Right Way to Do It
If our programs can take complex parameters or multiple filenames, we
shouldn’t handle sys.argv directly. Instead, we should use
Python’s argparse library, which handles common cases in a
systematic way, and also makes it easy for us to provide sensible error
messages for our users. We will not cover this module in this lesson but
you can go to Tshepang Lekhonkhobe’s Argparse
tutorial that is part of Python’s Official Documentation.
We can also use the argh library, a wrapper around the
argparse library that simplifies its usage (see the argh documentation for
more information).
Handling Multiple Files
The next step is to teach our program how to handle multiple files. Since 60 lines of output per file is a lot to page through, we’ll start by using three smaller files, each of which has three days of data for two patients:
OUTPUT
small-01.csv small-02.csv small-03.csvOUTPUT
0,0,1
0,1,2OUTPUT
0.333333333333
1.0Using small data files as input also allows us to check our results more easily: here, for example, we can see that our program is calculating the mean correctly for each line, whereas we were really taking it on faith before. This is yet another rule of programming: test the simple things first.
We want our program to process each file separately, so we need a
loop that executes once for each filename. If we specify the files on
the command line, the filenames will be in sys.argv, but we
need to be careful: sys.argv[0] will always be the name of
our script, rather than the name of a file. We also need to handle an
unknown number of filenames, since our program could be run for any
number of files.
The solution to both problems is to loop over the contents of
sys.argv[1:]. The ‘1’ tells Python to start the slice at
location 1, so the program’s name isn’t included; since we’ve left off
the upper bound, the slice runs to the end of the list, and includes all
the filenames. Here’s our changed program
readings_03.py:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
for filename in sys.argv[1:]:
data = numpy.loadtxt(filename, delimiter=',')
for row_mean in numpy.mean(data, axis=1):
print(row_mean)
if __name__ == '__main__':
main()and here it is in action:
OUTPUT
0.333333333333
1.0
13.6666666667
11.0The Right Way to Do It
At this point, we have created three versions of our script called
readings_01.py, readings_02.py, and
readings_03.py. We wouldn’t do this in real life: instead,
we would have one file called readings.py that we committed
to version control every time we got an enhancement working. For
teaching, though, we need all the successive versions side by side.
Handling Command-Line Flags
The next step is to teach our program to pay attention to the
--min, --mean, and --max flags.
These always appear before the names of the files, so we could do
this:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
action = sys.argv[1]
filenames = sys.argv[2:]
for filename in filenames:
data = numpy.loadtxt(filename, delimiter=',')
if action == '--min':
values = numpy.amin(data, axis=1)
elif action == '--mean':
values = numpy.mean(data, axis=1)
elif action == '--max':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
if __name__ == '__main__':
main()This works:
OUTPUT
1.0
2.0but there are several things wrong with it:
mainis too large to read comfortably.If we do not specify at least two additional arguments on the command-line, one for the flag and one for the filename, but only one, the program will not throw an exception but will run. It assumes that the file list is empty, as
sys.argv[1]will be considered theaction, even if it is a filename. Silent failures like this are always hard to debug.The program should check if the submitted
actionis one of the three recognized flags.
This version pulls the processing of each file out of the loop into a
function of its own. It also checks that action is one of
the allowed flags before doing any processing, so that the program fails
fast:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
action = sys.argv[1]
filenames = sys.argv[2:]
assert action in ['--min', '--mean', '--max'], \
'Action is not one of --min, --mean, or --max: ' + action
for filename in filenames:
process(filename, action)
def process(filename, action):
data = numpy.loadtxt(filename, delimiter=',')
if action == '--min':
values = numpy.amin(data, axis=1)
elif action == '--mean':
values = numpy.mean(data, axis=1)
elif action == '--max':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
if __name__ == '__main__':
main()This is four lines longer than its predecessor, but broken into more digestible chunks of 8 and 12 lines.
Handling Standard Input
The next thing our program has to do is read data from standard input
if no filenames are given so that we can put it in a pipeline, redirect
input to it, and so on. Let’s experiment in another script called
count_stdin.py:
PYTHON
import sys
count = 0
for line in sys.stdin:
count += 1
print(count, 'lines in standard input')This little program reads lines from a special “file” called
sys.stdin, which is automatically connected to the
program’s standard input. We don’t have to open it — Python and the
operating system take care of that when the program starts up — but we
can do almost anything with it that we could do to a regular file. Let’s
try running it as if it were a regular command-line program:
OUTPUT
2 lines in standard inputA common mistake is to try to run something that reads from standard input like this:
i.e., to forget the < character that redirects the
file to standard input. In this case, there’s nothing in standard input,
so the program waits at the start of the loop for someone to type
something on the keyboard. Since there’s no way for us to do this, our
program is stuck, and we have to halt it using the
Interrupt option from the Kernel menu in the
Notebook.
We now need to rewrite the program so that it loads data from
sys.stdin if no filenames are provided. Luckily,
numpy.loadtxt can handle either a filename or an open file
as its first parameter, so we don’t actually need to change
process. Only main changes:
PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
action = sys.argv[1]
filenames = sys.argv[2:]
assert action in ['--min', '--mean', '--max'], \
'Action is not one of --min, --mean, or --max: ' + action
if len(filenames) == 0:
process(sys.stdin, action)
else:
for filename in filenames:
process(filename, action)
def process(filename, action):
data = numpy.loadtxt(filename, delimiter=',')
if action == '--min':
values = numpy.amin(data, axis=1)
elif action == '--mean':
values = numpy.mean(data, axis=1)
elif action == '--max':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
if __name__ == '__main__':
main()Let’s try it out:
OUTPUT
0.333333333333
1.0That’s better. In fact, that’s done: the program now does everything we set out to do.
PYTHON
import sys
def main():
assert len(sys.argv) == 4, 'Need exactly 3 arguments'
operator = sys.argv[1]
assert operator in ['--add', '--subtract', '--multiply', '--divide'], \
'Operator is not one of --add, --subtract, --multiply, or --divide: bailing out'
try:
operand1, operand2 = float(sys.argv[2]), float(sys.argv[3])
except ValueError:
print('cannot convert input to a number: bailing out')
return
do_arithmetic(operand1, operator, operand2)
def do_arithmetic(operand1, operator, operand2):
if operator == 'add':
value = operand1 + operand2
elif operator == 'subtract':
value = operand1 - operand2
elif operator == 'multiply':
value = operand1 * operand2
elif operator == 'divide':
value = operand1 / operand2
print(value)
main()PYTHON
import sys
import glob
def main():
"""prints names of all files with sys.argv as suffix"""
assert len(sys.argv) >= 2, 'Argument list cannot be empty'
suffix = sys.argv[1] # NB: behaviour is not as you'd expect if sys.argv[1] is *
glob_input = '*.' + suffix # construct the input
glob_output = sorted(glob.glob(glob_input)) # call the glob function
for item in glob_output: # print the output
print(item)
return
main()PYTHON
# this is code/readings_07.py
import sys
import numpy
def main():
script = sys.argv[0]
action = sys.argv[1]
filenames = sys.argv[2:]
assert action in ['-n', '-m', '-x'], \
'Action is not one of -n, -m, or -x: ' + action
if len(filenames) == 0:
process(sys.stdin, action)
else:
for filename in filenames:
process(filename, action)
def process(filename, action):
data = numpy.loadtxt(filename, delimiter=',')
if action == '-n':
values = numpy.amin(data, axis=1)
elif action == '-m':
values = numpy.mean(data, axis=1)
elif action == '-x':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
main()PYTHON
# this is code/readings_08.py
import sys
import numpy
def main():
script = sys.argv[0]
if len(sys.argv) == 1: # no arguments, so print help message
print("Usage: python readings_08.py action filenames\n"
"Action:\n"
" Must be one of --min, --mean, or --max.\n"
"Filenames:\n"
" If blank, input is taken from standard input (stdin).\n"
" Otherwise, each filename in the list of arguments is processed in turn.")
return
action = sys.argv[1]
filenames = sys.argv[2:]
assert action in ['--min', '--mean', '--max'], (
'Action is not one of --min, --mean, or --max: ' + action)
if len(filenames) == 0:
process(sys.stdin, action)
else:
for filename in filenames:
process(filename, action)
def process(filename, action):
data = numpy.loadtxt(filename, delimiter=',')
if action == '--min':
values = numpy.amin(data, axis=1)
elif action == '--mean':
values = numpy.mean(data, axis=1)
elif action == '--max':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
if __name__ == '__main__':
main()PYTHON
# this is code/readings_09.py
import sys
import numpy
def main():
script = sys.argv[0]
action = sys.argv[1]
if action not in ['--min', '--mean', '--max']: # if no action given
action = '--mean' # set a default action, that being mean
filenames = sys.argv[1:] # start the filenames one place earlier in the argv list
else:
filenames = sys.argv[2:]
if len(filenames) == 0:
process(sys.stdin, action)
else:
for filename in filenames:
process(filename, action)
def process(filename, action):
data = numpy.loadtxt(filename, delimiter=',')
if action == '--min':
values = numpy.amin(data, axis=1)
elif action == '--mean':
values = numpy.mean(data, axis=1)
elif action == '--max':
values = numpy.amax(data, axis=1)
for val in values:
print(val)
main()PYTHON
import sys
import numpy
def main():
script = sys.argv[0]
filenames = sys.argv[1:]
if len(filenames) <=1: #nothing to check
print('Only 1 file specified on input')
else:
nrow0, ncol0 = row_col_count(filenames[0])
print('First file %s: %d rows and %d columns' % (filenames[0], nrow0, ncol0))
for filename in filenames[1:]:
nrow, ncol = row_col_count(filename)
if nrow != nrow0 or ncol != ncol0:
print('File %s does not check: %d rows and %d columns' % (filename, nrow, ncol))
else:
print('File %s checks' % filename)
return
def row_col_count(filename):
try:
nrow, ncol = numpy.loadtxt(filename, delimiter=',').shape
except ValueError:
# 'ValueError' error is raised when numpy encounters lines that
# have different number of data elements in them than the rest of the lines,
# or when lines have non-numeric elements
nrow, ncol = (0, 0)
return nrow, ncol
main()PYTHON
import sys
def main():
"""print each input filename and the number of lines in it,
and print the sum of the number of lines"""
filenames = sys.argv[1:]
sum_nlines = 0 #initialize counting variable
if len(filenames) == 0: # no filenames, just stdin
sum_nlines = count_file_like(sys.stdin)
print('stdin: %d' % sum_nlines)
else:
for filename in filenames:
nlines = count_file(filename)
print('%s %d' % (filename, nlines))
sum_nlines += nlines
print('total: %d' % sum_nlines)
def count_file(filename):
"""count the number of lines in a file"""
f = open(filename, 'r')
nlines = len(f.readlines())
f.close()
return(nlines)
def count_file_like(file_like):
"""count the number of lines in a file-like object (eg stdin)"""
n = 0
for line in file_like:
n = n+1
return n
main()